Multi-Agent GenAI
GenAI | Multi-Agent | Capstone Project | Tata Consultancy Services
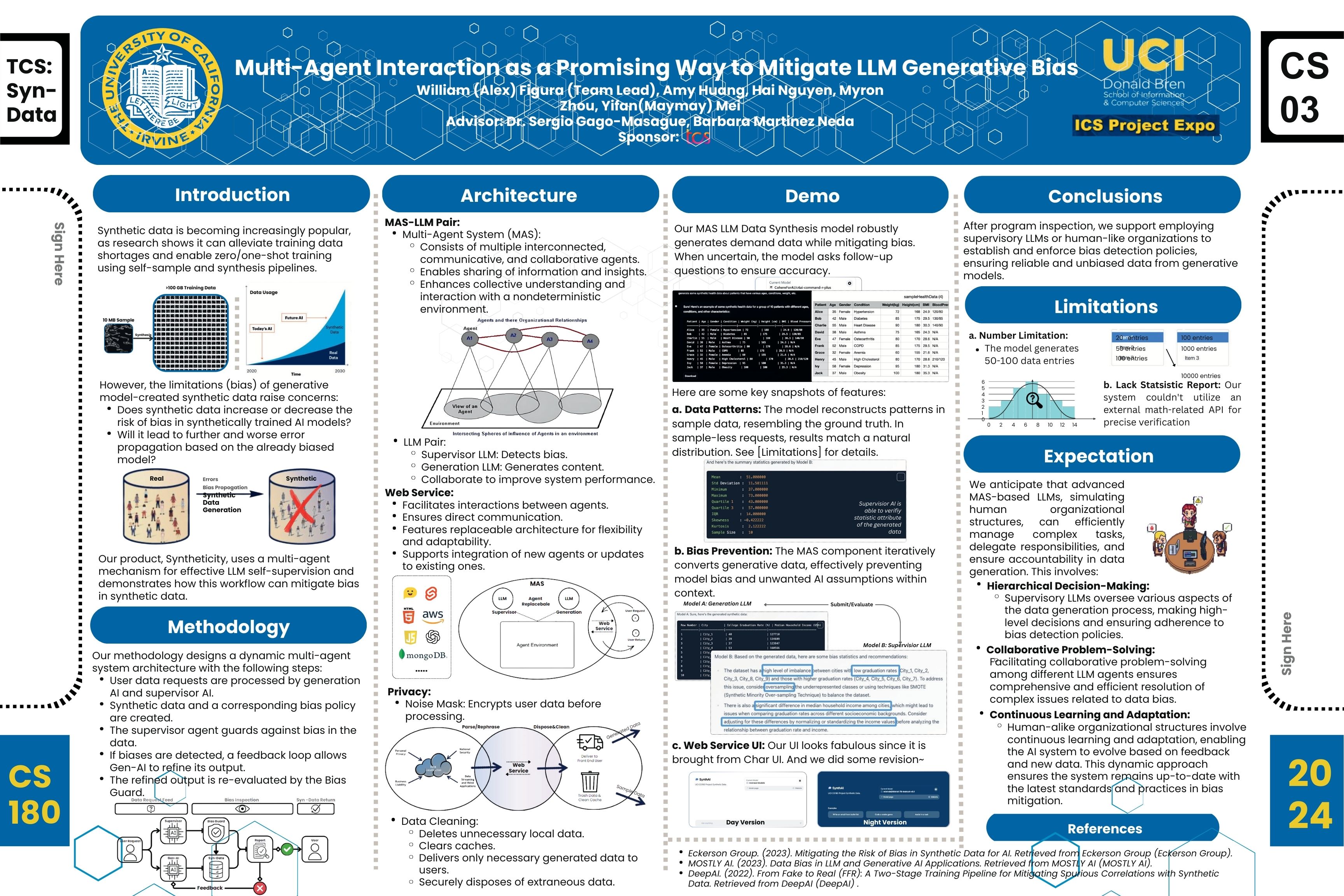
View on GitHubIntroduction
The current landscape for synthetic data generation primarily relies on domain-specific algorithms and generative adversarial networks (GANs) or large language models to produce data, namely formatted text and tabular data, that mimics real-world distributions. While effective in certain contexts, these solutions often face challenges in generating complex, multi-modal data and ensuring minimal data hallucination, which will create non-realistic or implausible data points that compromise the data quality.
Goal
Our project introduces a reinvention using a multi-agent network large language model (MA-LLM) framework designed to address these limitations. This approach enables generating high-quality, cross-modality synthetic data with greater adherence to real-world distributions and contexts while providing maximized efficiency. By integrating multi-agent specialized in different data modalities, our platform significantly reduces the occurrence of hallucinations, ensuring that the generated synthetic data is both realistic and diverse.
Key Features
- Multi-Agent System (MAS) LLM Data Synthesis model
- Generate data while mitigating bias
- LLM pair: (1) Supervisor LLM to detect bias, (2) Generation LLM to generate content
- Web Service UI adopted from HuggingFace ChatUI
Technologies Used
LLMs, AI Models (e.g., claude-2.1, gpt-4, mistral-7b), HuggingFace, MongoDB, TypeScript, Svelte, HTML, CSS, Dockerfile, Shell
Gallery
Poster